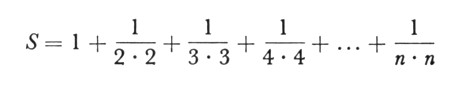Readability and comprehensibility are amongst the most important attributes of a program. Readability can be defined as how easy a piece of software is to read and understand. There are a number of programmers that love to write complicated code. Sometimes it is because they are trying to be clever, and other times because they haven’t quite thought through the logic of the code they are writing. Consider the following algorithm snippet:
! Check code for things that go bump in the night
if (not(engineCheckfail()) andnot(parkBreakOn()) andnot(wheelChocks())) then
! algorithm to taxi plane
end
A more readable piece of code would involve changing both the comment, and the logic of the conditional, even if it means changing the subprograms that return values.
! Check conditions for plane to taxi - if the engineCheck is okay and
! the park break is off, and wheel chocks have been removed, the plane can taxi
if (engineCheck() and parkBreakOff() and wheelChocksRemoved()) then
! algorithm to taxi plane
end
Here is another example of a piece of Fortran code (adapted from The Elements of Programming Style, Kernighan and Plauger):
do i = 1, n
do j = 1, n
V(i,j) = (i/j) * (j/i)
enddoenddo
This tricky piece of code creates an identify matrix. In Fortran integer division truncates to zero, so when I<j, i/j is zero, and when j<i, j/i is zero. When both i and j are equal, (i/j) * (j/i) = 1. Basically this code adds 1’s on the diagonal. It’s a neat piece of code, but there are easier ways of doing this, without having to add a comment to explain what is going on, and without having to use two integer divisions and a multiplication. Below is a more readable version of the code.
do i = 1, n
do j = 1, n
if (i == j) then
V(i,j) = 1
else
V(i,j) = 0
end ifend do
enddo
But this can be improved even further, without loosing anything in the way of readability.
V = 0
do i = 1, n
V(i,i) = 1
enddo
Bottom line? Don’t write clever code that isn’t readable, or isn’t properly documented.
People often design algorithms, but implement them very poorly. They concentrate on the accuracy issues and forget many of the other characteristics that make an algorithm. Although correctness is extremely important, it is surprising how many published algorithms fail to identify what they actually do and the circumstances around which they function.
In many respects, algorithms have to be translatable to any language, and portable to any platform. Dependency on particular machines, hardware, or programming libraries all make algorithms less universal. An algorithm should also be intelligible. If only the person designing the algorithm actually understands it, it is much more challenging to make it universal. A lack of intelligibility makes it harder to port or translate, often resulting in inefficient and inelegant code. Algorithm robustness is also important because most users of the algorithm will treat it like a black-box – they may understand how it functions, but not how it is implemented. Lastly there is efficiency. Making an algorithm run faster is certainly important, but not at the expense of any of the above criteria.
First there is correctness. This can be achieved in most programs using the following basic criteria:
Test all statements – Has every path in the program been tested using appropriate test data? What happens when something fails? Is there some level of redundancy?
Initialization – Are all variables and aggregate structures assigned values before they are used?
Overflow and underflow – Could the evaluation of an expression somewhere lead to overflow or underflow? Is the data type being used appropriate for the calculations being performed?
Array subscripts – Are the correct array subscripts being used in an expression? Are the array subscripts within the bounds of the array?
Extreme test cases – Has the algorithm been tested on any extreme test cases? Does a sorting algorithm work with a list of 1,000 integers, 50,000 integers?
Universality is less of an issue nowadays, however there are sometimes algorithms, such as those written in Matlab or Python that make use of libraries which are not universal. Trying to replicate such algorithms in other languages is both challenging and time consuming. Intelligible algorithms are those with clarity. An algorithm implemented in any language should be easy to read, and well documented. Compactness of code (here’s looking at you C) is good, but only in so far that in can be interpreted by the algorithm’s user. Some things are as simple as naming identifiers. Don’t use identifiers that can be confused with basic built-in functions, or identifiers such as I (capital eye), l (small ell), O (capital oh), o (small oh), because they are far too often confused with the digits 1 and 0.
Robustness is key to a good algorithm, and it is seemingly good practice to implement some form of defensive programming, i.e. better to over-check than under-check. For example the following implementation of a Fortran factorial algorithm works well, but contains no check on the validity of n.
integer (kind=int64) function factorial(n)
implicit none
integer, intent(in) :: n
integer :: i
integer (kind=int64) :: f
f = 1
do i = 2, n
f = f * i
end do
factorial = f
end function factorial
The upper value of int64 is 9223372036854775807, so the maximum value of n! calculated can be 20!, which is 2432902008176640000. This means that the function will fail if n is not 1 < n < 21.
Finally there is efficiency. This is less of an issue than it once was, but there are still things that can be done to ensure things go a little faster, or are less susceptible to failure. Here are some things to consider:
Recursion – Don’t use recursion if a simple loop will work. There are many instances where recursion provides the most efficient algorithm, e.g. Quicksort, but use it sparingly, and only if the resources are available. There is a reason why NASA’s software rules forbid the use of recursion.
Repetition – Do not calculate the same value more than once.
Multiplication – Multiplication is usually faster than exponentiation. These things still matter if performing millions of calculations.
In one word, yes. Amazingly easy. In fact, you don’t even need any fancy software or a compiler. All you need is an editor, and a browser. And you don’t need *any* programming experience. Nada. Sure, fancy websites have a lot of other things going on – they use languages like Javascript to do things like create active webpages. Now if you want something like a E-commerce capabilities, I suggest going elsewhere, like Squarespace – I wouldn’t build these sort of platforms from scratch. I mean, honestly I wouldn’t build any sort of website from scratch. I write four blogs, and use WordPress for all of them, because I care about the content I am writing, not the technology behind it. Having said that, having some knowledge of HTML, and CSS does help you with WordPress, especially if you decide to go WordPress standalone on your own server.
Now HTML stands for Hypertext Markup Language, so while technically its a language, it’s not really a programming language, mainly because it doesn’t have any of the same “control structures” as found in languages such as C or Java. It is more like LaTeX. HTML is also quite forgiving from a programming context. If you try to add an image, and it doesn’t show when you load the page, then you know there is something wrong. Step 1 is finding an editor. Good ones are atom, and BBEdit. Then pick a browser you like to work with – Firefox, Chrome, Opera, Safari. Then just begin writing HTML and experimenting with things.
Here is a simple piece of HTML code that prints “Hello World!”:
The basics are all in here. The <head> is where the definitions for the webpage go. You will notice an element called <title>. This specifies the words that show up in the browser tab, in this case “HTML Example”. The <body> contains the main parts of the webpage that are displayed. This example contains a <p> element, which defines a paragraph of text. In this case, it shows the text “Hello World!” in the default browser font. From here it is possible to structure the website, add images, and style the content using CSS. For example to add some simple internal styling to change the font being used is as simple as adding:
In some respects, once you have a basic design, HTML and CSS can be used together with a bit of trial-and-error to see what works best. Sometimes ideas that look good on paper don’t seem aesthetically pleasing, or are too complex to implement. Remember though, Learning HTML does not make you a programmer per se. HTML is used for structural purposes, and doesn’t do anything in the same sense as programming languages.
One of the most important features for the construction of programs is the assignment. It was first introduced by Zuse, as the double arrow, ⟹, which he called the Ergibt-zeichen (results or yields sign). The ⟹ symbol represents “implies” in math symbology, meaning that A⟹B, means “if A is true, then B is true“. The systematic use of an assignment constituted a distinct break between computer-science thinking and mathematical thinking [6]. When Zuse introduced the new symbol, he remarked that Z3 + 1 ⟹ Z3 was analogous to the more traditional Z3.i + 1 ⟹ Z3.i+1 [7]. The interesting thing about this symbol is the fact that it directs the flow of information. For example in Plankalkül:
Z + 1 ⟹ Z
This obviously implied that the result of 1 added to the value of Z would be stored in Z. In the original manuscript [8], the symbol is shown as , however Zuse never actually used the symbol. At the time it was considered one of the more important features in the construction of programs. Rutishauser used the symbol, in Superplan. In the preliminary work on the language which was to become Algol 58 this evolved into => with the requirement that formula were written in an “appropriate way” [4]. The concept here was to write to the left of the “ergibt” symbol “=>” (ergibt roughly translates to results or yields) the arithmetic expression to be evaluated and to the right the designation of the new quantity defined by the calculation [5]. This ergibt symbol was considered a better choice fore the dynamic flow of the program than the equality symbol.
((a×b)+c) => s
s + 2 => s
For example above, “old” s plus 2 yields “new” s. Interestingly, in the earliest form of the new language, the symbol := was used in the for loop [5]. For example:
for i := 1...n
By the time the design of Algol 58 was finalized, := was chosen, and it has been suggested that this only occurred because the American group pressured the Europeans, who would have preferred to use Zuse’s symbol. Why := was chosen is uncertain. It is possible that it was to represent a left facing arrow, although why <− was not chosen is uncertain. Even the use of <= would have been more meaningful (at the time ≤ was used to represent less-than, as opposed to <=).
By the time of the discussions on the design of ALGOL 60 at the Zurich ACM-GAMM Conference (1958), there is no doubt that there were preconceived notions on the part of the American contingent due to their “experience with FORTRAN” [1]. This is amply shown in the discussion on the operation of assignment. The natural flow of computation is a notation of the form b+7⟶z. However the American’s preferred the reverse [1]. Algol 60 also used the := operator. Algol 60 lended its assignment operator to Algol 68, which was also adopted by Pascal (and its descendants), and Ada.
The use of = as the assignment operator harkens back to Fortran [2]. Here it was touted that a Fortran arithmetic formula closely resembles a conventional arithmetic formula, “it consists of the variable to be computed, followed by an = sign, followed by an arithmetic expression” [2]. The problem is that an expression such as “x=x+1” would be mathematically interpreted as “0=1”. Fortran used the = operator for both initialization, and reassignment.
initialization: x = 1
reassignment: x = x + 1
This was really a poor notational decision, as the = operator is more classically associated with equality. Fortran initially avoided this confusion somewhat because the logical if statement did not appear until Fortran IV in 1965, and even then it used .EQ. as the equality operator. PL/I would use the = for both assignment and equality. But neither Fortran nor PL/I were the direct source of the use of = as a contemporary assignment operator in languages such as C.
In 1963 work began by Christopher Strachey, at the University of Cambridge, on a language which would innovate from Algol 60 – CPL (originally short for Cambridge Programming Language, but later Combined Programming Language). This was a case of a theoretical language never fully implement, but a language doesn’t have to be implemented to have influence. CPL introduced the concept of initialized definition [3], which existed in three forms. The most interesting one is “initialization by value”, implying that when a variable is defined, it may be assigned an initial value obtained by evaluating an expression. For example:
integer x = 37
CPL also included initialization “by reference” (≃), and by substitution (≡). Add to this the use of := for reassignment. The problem now was that = was used for both initialization and equality. At the time CPL was never really implemented, partially because of its size and complexity. The complexity was removed, eventually resulting in BCPL (Basic CPL), designed by Martin Richards in 1967. Among its simplifications, the “three forms of initialization” had to go. The initializations were reduced to a simple =, with := for reassignment, and = for equality. Ken Thompson wanted to convert BCPL to run on the PDP-7. The problem here was that although the BCPL compiler was small, it was still larger than the minimum working memory available on the PDP-7. The solution? Create an even more minimalistic language, B. This resulted in the merging of initialization and reassignment into one operator, =. This made assignment and equality somewhat ambiguous, so Thompson added a new equality operator, == . Thompson was suppose to have noted that “Since assignment is about twice as frequent as equality testing in typical programs, it’s appropriate that the operator be half as long.“. B of course evolved into C. B also introduced a cornucopia of assignment statements some of which would find their way into C. This included 16 assignment operators: =, =|, =&, ===, =!=, =<, =<=, =>, =>=, =<<, =>>, =+, =−, =%, =*, and =/ .
Along other assignment operator roads not taken are symbols derived from languages such as APL. Ken Iverson introduced APL ion 1966, and used ← for all assignments. As keyboards changed and lesser known symbols disappeared, even Iverson changed it to =: in his language J. APL influenced S, which in turn influenced R, which uses <− as the assignment operator.
Language
Assignment
Equality
Fortran
=
.eq. (FortranIV) == (Fortran 90)
Algol 60, Algol68
:=
=
APL
←
=
Pascal (+ descendants), Ada
:=
=
C (+ descendants)
=
==
Naur, P., “The European side of the last phase of development of Algol 60”, History of Programming Languages, pp.92–139 (1978)
Backus, J.W., et al. The Fortran Automatic Coding System for the IBM 704 EDPM, IBM (1956)
Barron, D.W., et al. “The main features of CPL”, The Computer Journal, 6(2), pp.134-143 (1963)
Rutishauser, H., “Automatische Rechenplanfertigung bei programmgesteuerten Rechenmaschinen” (1952)
Knuth, D.E., Pardo, L.T., “The early development of programming languages.” Technical Report, Stanford University (1976)
Zuse, K., “Der Plankalkül”, Manuscript prepared in 1945, published in “Berichte der Gesellschaft für Mathematik und Datenverarbeitung , No. 63 (Bonn, 1972), part 3, 285 pp. English translation in No. 106 (Bonn, 1976), pp.42-244.
Zuse, K., “Über den allgemeinen Plankalkül als Mittel zur Formulierung schematisch kombinativer Aufgaben”, Archiv der Math. 1 (1948/49), pp.441-449.
Language design in the 1960’s was dominated by attempts to improve upon Algol60. Hoare noted in 1973 [1] that ALGOL-60 was “… a language so far ahead of its time, that it was not only an improvement on its predecessors, but also on nearly all its successors”. Niklaus Wirth was a graduate student at University of California, Berkeley when he started playing around with languages. He joined a research group which was engaged with the implementation and improvement of a dialect of ALGOL-58, NELIAC. He described the compiler as “an intricate mess“, and the process one of “1% science, and 99% sorcery” [1].
The first language Wirth designed leading to his dissertation was Euler, as Wirth himself put it “a trip with the bush knife through the jungle of language features and facilities” [1]. Euler had academic elegance, but no real practical value, however it did catch the attention of the IFIP Working Group, engaged in designing the successor to ALGOL-60. There seemed to be two camps here, one which wanted to push the boundaries of language design and another which wanted to extend ALGOL-60. Wirth belonged to the latter group. In 1965, three reports by Wirth, Seegmüller, and Wijngaarden described three different quasi-complete languages. The complexity of the design process, involving far too many people, eventually led Wirth to become disheartened with the design process, and he went off to develop his own version of ALGOL-60s successor. Designed with contributions from Tony Hoare, this language would become ALGOL-W.
Wirth’s languages ad their influences (core languages in darker blue, external languages in orange)
Wirth’s first significant language was PL360, a byproduct of the ALGOL-W effort. The IBM 360 upon which ALGOL-W was implemented offered the choice of assembly language or Fortran compilers, neither of which was very attractive. PL360 [2] was a tool with which to implement ALGOL-W. ALGOL-W had a number of applications, but was deficient as a systems programming language. PL360 was to become more successful than ALGOL-W, largely because ALGOL-W was a complex language, and the target computers inadequate. In the fall of 1967, Wirth returned to Switzerland to begin work on the language that would become most closely associated with his language design efforts – Pascal. Wirth would go on to create a trinity of languages, neither of which were that closely related, but all that had one thing in common, they were “ALGOL-like” languages – Pascal, Modula-2 and Oberon.
Pascal – Based largely on Algol W, including the use of it’s while and case statements, and record structures. There were syntactic differences, however Algol 60 was almost a subset of Pascal.
Modula-2 – Wirth noted that Modula-2 “includes all aspects of Pascal, and extends them with the module concept”.
Oberon – Evolved from Modula-2 by very few additions, and several subtractions.
The influence of Wirth’s languages on other languages (shown in red)
Note that “ALGOL-like” really implied – a procedural paradigm, a rigorously defined syntax, traditional mathematical notation (with the nonsense of symbols like ++), block structure providing identifier scope, the availability of recursion, and a strict, static data typing system. [3]
[1] Wirth, N., “From programming language design to computer construction”, CACM, 28(2), pp. 160-164 (1985) [2] Wirth, N., “PL360, a programming language for the 360 computers”, Journal of the ACM, 15(1), pp.34-74 (1968) [3] Wirth, N., “Modula-2 and Oberon”, in ACM Conf. on History of Programming Languages, pp.3-1-3-10 (2007)
Algol was the first real “algorithmic” language, more so than Fortran because the latter contained a lot of structures that we couldn’t consider pleasant, and most of them had to do with what is considered breaking the sequential flow. In early Fortran there were a lot of “jump” statements, either explicitly goto, or thinly veiled as goto (see arithmetic if). In early languages goto (or go to) was often used in place of repetitive statements, either because the programmer was use to jumps (from assembler), mistrusted loops, or just didn’t consider them. Algol used the go to statement and associated labels to break the sequential flow.
Consider the arithmetic sequence, S+1/n/n where S=0 initially, and n takes on a sequence of values 1,…,∞. This can be expressed as:
Of course ∞ makes for a lot of work, so it is easier to stop the process at some point, let’s say 1.6449 (π²/6). Here is an Algol program to perform the task:
This piece of code has two jumps. The first one, which uses the label L1 mimics a loop, repetitively processing the next value of n, until such time as S is greater-than-or-equal-to 1.6449, then the second jump is invoked to label L2, effectively exiting the loop.
As mentioned before, strings in Ada can be tricky. Normal strings are fixed in length, and Ada is very stringent about this. Consider a piece of code like this:
with ada.Text_IO; use Ada.Text_IO;
with ada.strings.unbounded; use ada.strings.unbounded;
procedure ustr2strfail is
function tub(Source : String) return unbounded_string renames ada.strings.unbounded.to_unbounded_string;
type lexicon is array(1..10) of unbounded_string;
words : lexicon := (tub("gum"),tub("sin"),tub("cry"),
tub("lug"),tub("star"),tub("fault"),tub("sleeper"),
tub("a"),tub("vader"),tub("nordic"));
aword : string(1..10);
begin
aword := to_string(words(7));
put(aword);
end ustr2strfail;
This will compile fine, however when it runs, the following error will propogate:
This means that although the unbounded string is converted to a string using the function to_string(), it only works if the length of the unbounded string equals the length of the string aword. So in the code above, aword has a length of 10, and when an attempt is made to assign it the unbounded string, “sleeper”, it fails. It would work if sleeper was padded out with 3 spaces after it. How to fix this? Do exactly that, pad the words. Here is a subroutine that does this:
with ada.Text_IO; use Ada.Text_IO;
with ada.strings.unbounded; use ada.strings.unbounded;
with ada.strings.unbounded.Text_IO; use ada.strings.unbounded.Text_IO;
with ada.strings.fixed; use ada.strings.fixed;
procedure ustr2str is
subtype string10 is string(1..10);
R : string10;
function tub(Source : String) return unbounded_string renames ada.strings.unbounded.to_unbounded_string;
type lexicon is array(1..10) of unbounded_string;
words : lexicon := (tub("gum"),tub("sin"),tub("cry"),
tub("lug"),tub("star"),tub("fault"),tub("sleeper"),
tub("a"),tub("vader"),tub("nordic"));
function padString(V: unbounded_string) return string10 is
temp : constant string := to_string(V);
res : string10;
begin
ada.strings.fixed.move(temp, res, drop=>ada.strings.right);
return res;
end padString;
begin
R := padString(words(7));
put(R);
end ustr2str;
It uses the procedure move(), from the ada.strings.fixed package. It has the following basic form:
procedure Move (Source : in String;
Target : out String;
Drop : in Truncation := Error;
Justify : in Alignment := Left;
Pad : in Character := Space);
The procedure move() copies characters from Source to Target. If Source has the same length as Target, then the effect is to assign Source to Target. If Source is shorter than Target then, Justify is used to place the Source into the Target (default = Left). Pad specifies the padding, default is Space. Drop is used if Source is longer than Target.
There are things that just niggle at you all the time. Most of us haven’t had to worry about the likes of scope that closely in decades. You create a global variable, it’s global. You create a variable inside a subprogram, it’s local to that subroutine. Simple right? The problem comes then with dynamically typed languages where variables don’t need to be declared before they are used. They are “declared” at the time of use. So a variable used within a loop for the first time, should be accessible after the loop is finished. I mean that’s how it works in Python. But that’s not how it works in Julia. Consider a piece of Julia code like this:
for i in 1:10
x = i + i
end
println(x)
Now the println() will fail because the scope of x is inside the for loop, and result in a “x not defined” message. If we try to make x “global” by setting it to zero before the loop (and changing the expression to sum the values of i):
x = 0
for i in 1:10
x = x + i
end
println(x)
It fails again, leading to a message of the form:
Warning: Assignment to x in soft scope is ambiguous because a global variable by the same name exists: x will be treated as a new local. Disambiguate by using local x to suppress this warning or global x to assign to the existing global variable.
This is because although global variables exist in all scopes, from Julia V1.0 on they are read-only in local scopes. This means that in order for this to work, access to global variables must be made explicit (otherwise it is read only in the local scope of the loop).
x = 0
for i in 1:10
global x = x + i
end
println(x)
This is extremely annoying to say the least. But, wait it gets even more stupid. There is an exception to the rule, from the perspective of using syntax anyway. If we encapsulate the second piece of code inside a function, it works.
function sum(n)
x = 0
for i in 1:n
x = x + i
end
return x
end
println(sum(10))
I don’t quite get why the same code acts differently in different circumstances, and it is likely even more confusing for the novice programmer. When x=0 is executed, x will become a new local variable in the body of the function. The for loop has its own inner local scope within the function scope. At the point where x=x+i occurs, x is already a local variable, so the assignment updates the existing x instead of creating a new local variable. So the same code in two places acts differently.
This is a good example of when language designers do something that just doesn’t make sense. Maybe it’s because there are so many people involved in the design of Julia. A global variable is by its very nature, global.
If you are thinking about using Julia to implement recursive algorithms, forget it. It just won’t work properly, well not unless you have some idea what the depth of recursion will be… but that’s hardly the point of recursion. So you could likely do Fibonacci(40) with few problems. Anything with indeterminate recursive depth, or a lot of internal variables though will suffer at the hands of Julia.
The hard limit a the stack size (kbytes) on a system can be found using ulimit, but its no panacea:
% ulimit -Hs
65520
Which is seemingly still a lot, at 65 megabytes (on OSX 11.1). The problem with Julia is weird, because Python has similar constraints, yet is able to run Slowsort(). Julia produces the following error when faced with sorting a mere 25 numbers:
ERROR: LoadError: StackOverflowError:
Stacktrace:
[1] recur(::String) at /recur.jl:2 (repeats 79984 times)
in expression starting at /recur.jl:5
This is different to Python, which also has issues with recursion, but there is it based on the value of the “recursion limit”, or depth of the recursion. In Python this can be fixed by setting new depth:
sys.setrecursionlimit(100000)
Julia on the other hand does not have an internal limit to the stack size, but uses the limits of the operating system. Now this doesn’t mean recursive depth. How many recursive calls will fit on the stack then depends upon both your system and the complexity of the function itself. Now let’s do an experiment. With the system stack set at max, we will run the following simple recursive function, with very little in the way of resource overhead.
function recur(var::String)
recur("Ai")
end
recur("ai")
The outcome is still the same, a stack overflow. But the value 79984 is repeated. So what is going on here? To dig deeper, we calculate the depth of recursion before failure (DORBF). All we really do is count the number of times the function is called.
x = 0
function recur(var::String)
global x = x + 1
print(x," ")
recur("A")
end
recur("a")
In this case the depth of recursion is 209,181, which is reasonably deep. If we apply the same principle to the Slowsort() function, we get a depth of 130,738.
The moral of the story is don’t use Julia for recursion, I mean it really was never designed for that.
Some algorithms were never meant to be important, or efficient, they just exist. Slowsort is one of those algorithms, thrown into the ether for some reason. The algorithm was published in 1986 by Andrei Broder and Jorge Stolfi in their paper Pessimal Algorithms and Simplexity Analysis [1] where they explored a series of sub-optimal algorithms. The authors described it as an “elegant recursive algorithm“. The slowsort algorithm is a good example of what is termed the multiply and surrender paradigm.
The algorithm consists of sorting n numbers, A1, A2, …, An into ascending order following this simple algorithm: (i) find the maximum of the numbers and (ii) sort the remaining numbers. The first part of the algorithm can be further decomposed:
1. Find the maximum of the list containing the first 1..n/2 elements.
2. Find the maximum of the list of remaining n/2+1..n elements.
3. Find the largest of the two maxima, which is placed at the end of the array.
Steps (1) and (2) can be solved by sorting the specified elements and taking the last element in the result. The original problem has then been multiplied into three simpler ones: (i) sort the first half; (ii) sort the second half; and (iii) sort all elements but one. This is continued recursively until the lists have at most one element, at which point the algorithm surrenders. Here is the complete algorithm:
subroutine slowsort(A, i, j)
if (i ≥ j) then
return
else
m = abs((i+j)/2)
slowsort(A, i, m)
slowsort(A, m+1, n)
if (Am > Aj) then
swap(Am,Aj)
end-if
slowsort(A, i, j-1)
end-if
end-subroutine
The lower bound of Slowsort is non-polynomial in nature and for a sufficiently large value of n this would be more than n^2 implying that even the best case of Slowsort is worse than the worst case of Bubble sort. Even running this code in C is slow. We tested it using 500 randomly generated integers. The Bubblesort took 0 seconds, while the Slowsort took 476 seconds. Not amazing (and trying it with a larger dataset isn’t even worth it).
A brief note on Multiply and Surrender
A basic multiply and surrender (MaS) problem solving paradigm consists of replacing the problem by two or more subproblems, each of which is marginally simpler than the original. The subproblems and subsubproblems are multiplied continuously in a recursive manner. At some point the subproblems will become so simple that they must be resolved, and they will “surrender”. This is similar to divide-and-conquer, however MaS procrastinates, making the entire process very inefficient, even though it does converge.